Enterprise AI & Private LLM Infrastructure
Select the hardware tier that matches your parameter size and inference/training requirements.
Server Configurations

Dell C4130 (SXM2)
$4,000+The ideal entry point for high-performance private AI. Utilizes the SXM2 socket for high-bandwidth NVLink communication (300 GB/s). Perfect for quantized 70B models.
- GPU Socket: NVIDIA SXM2
- Configuration: 4x Tesla V100
- Total VRAM: 64GB - 128GB

NVIDIA DGX-1
$12,000+The gold standard for deep learning. Doubles the density of the C4130 using SXM2 architecture with a "Cube Mesh" NVLink topology for massive parallel throughput.
- GPU Socket: NVIDIA SXM2
- Configuration: 8x Tesla V100
- Total VRAM: 128GB - 256GB

NVIDIA DGX-2
$40,000+A massive leap in AI architecture. Uses the SXM3 socket and NVSwitch to let 16 GPUs communicate simultaneously at 2.4 TB/s, creating a unified 512GB memory pool.
- GPU Socket: NVIDIA SXM3
- Configuration: 16x Tesla V100
- Total VRAM: 512GB (Unified)

HGX A100 Platform
$85,000+Commercial-grade production capability using the SXM4 socket. Features Ampere architecture with TensorFloat-32 and BF16 support for unprecedented speed.
- GPU Socket: NVIDIA SXM4
- Configuration: 8x A100
- Total VRAM: 320GB - 640GB

Supermicro SYS-4029GP
From $7,000+The ultimate DIY host. This 4U chassis supports 8x Double-Width PCIe GPUs. Features Dual Xeon Scalable processors, up to 6TB RAM, and massive airflow for running RTX 3090/4090 or Tesla cards.
- Form Factor: 4U Rackmount
- Capacity: 8x PCIe 3.0 x16 GPUs
- Processor: Dual Xeon Scalable

Dell PowerEdge R740
$4,000+Standard enterprise infrastructure for inference. Accepts standard PCIe accelerators (A10, T4, A2). A cost-effective solution for deploying tasks like RAG pipelines or chatbots.
- Type: Standard PCIe 3.0
- Capacity: Up to 3x Double-Width
- Cooling: Standard Air
Setup & Demonstration Tutorials
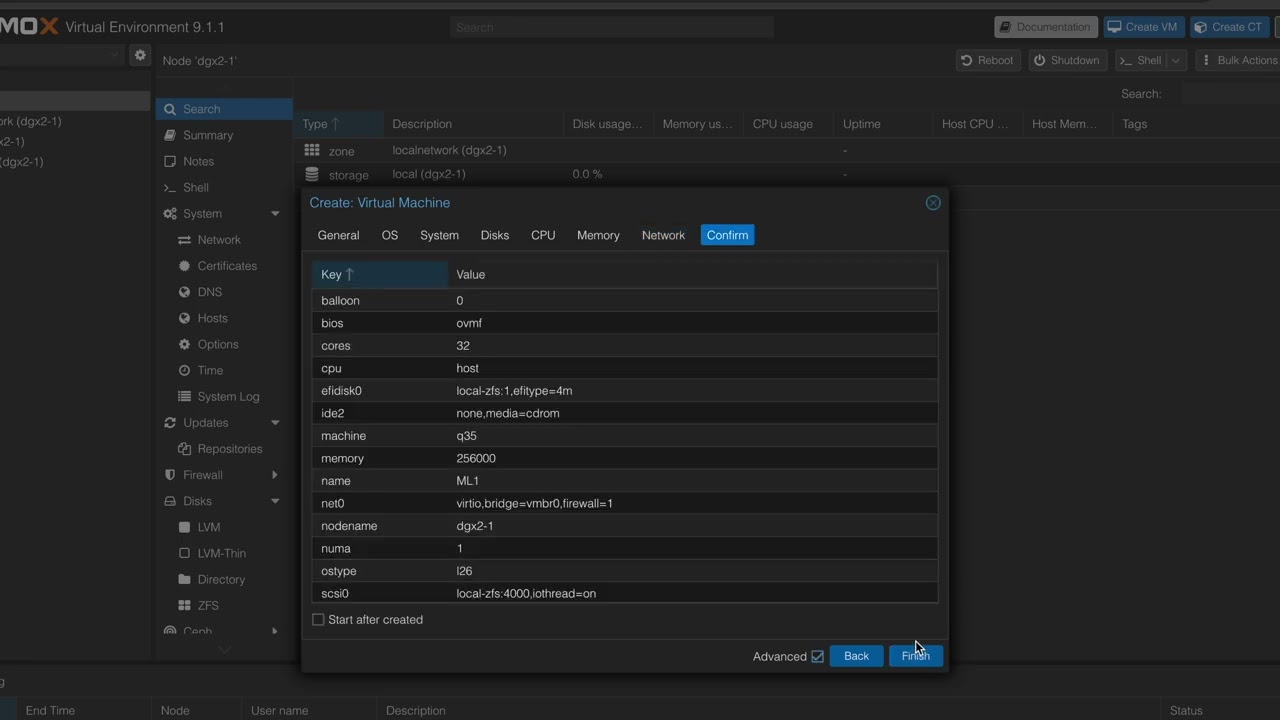
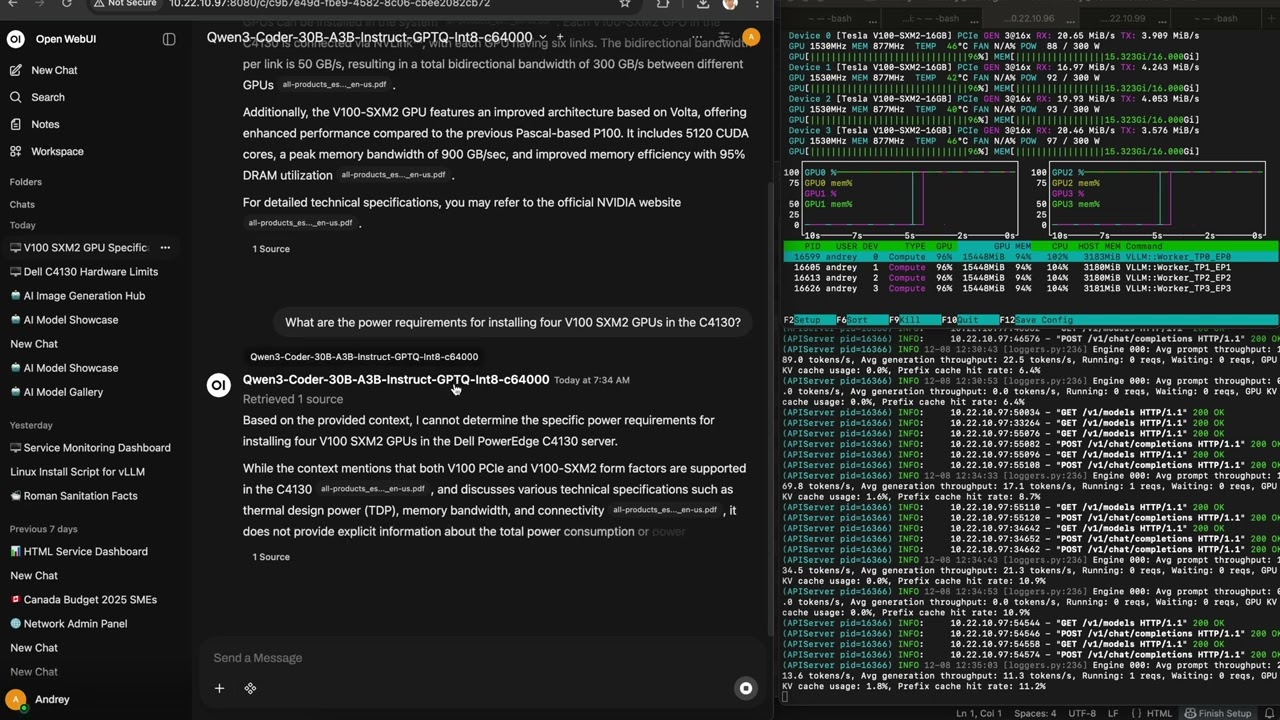
vLLM Launch Command Reference
vllm serve unsloth/Qwen3-14B-unsloth-bnb-4bit --port 8000 --served-model-name "qwen3-14b" --quantization bitsandbytes --gpu_memory_utilization 0.9 --pipeline_parallel_size 4
vllm serve QuantTrio/Qwen3-Coder-30B-A3B-Instruct-GPTQ-Int8 --port 8000 --served-model-name Qwen3-Coder-30B-A3B-Instruct-GPTQ-Int8 --enable-expert-parallel --gpu_memory_utilization 0.8 --tensor_parallel_size 4 --tokenizer "Qwen/Qwen3-Coder-30B-A3B-Instruct" --trust-remote-code --max-model-len 64000 --max-num-seqs 512 --swap-space 16
vllm serve Qwen/Qwen3-VL-8B-Instruct --port 8000 --served-model-name Qwen3-VL-8B --gpu_memory_utilization 0.9 --tensor_parallel_size 4 --trust-remote-code --max-model-len 32000 --max-num-seqs 512
vllm serve unsloth/DeepSeek-R1-Distill-Llama-70B-bnb-4bit --port 8000 --served-model-name DeepSeek-R1-Distill-Llama-70B-bnb-4bit --gpu_memory_utilization 0.9 --pipeline_parallel_size 4 --trust-remote-code --quantization bitsandbytes
vllm serve Qwen/Qwen3-30B-A3B --port 8000 --served-model-name "qwen3-30b" --gpu_memory_utilization 0.9 --pipeline_parallel_size 4 --enable-expert-parallel
vllm serve QuantTrio/Qwen3-Coder-30B-A3B-Instruct-GPTQ-Int8 --port 8000 --served-model-name Qwen3-Coder-30B-A3B-Instruct-GPTQ-Int8 --enable-expert-parallel --gpu_memory_utilization 0.8 --tensor_parallel_size 4 --tokenizer "Qwen/Qwen3-Coder-30B-A3B-Instruct" --trust-remote-code --max-num-seqs 512 --swap-space 16